
Web Scraping, Trend Ancaman Bisnis dan Teknologi Berikutnya
https://indosystem.com/wp-content/uploads/2016/06/spider_content-1-1024x536.jpg 1024 536 Dian Boyke Dian Boyke https://secure.gravatar.com/avatar/c9a775a9c29b76ec216f6fbfe8a2794d?s=96&d=mm&r=gWeb Scraping. Akhir-akhir ini kita sering menjumpai website-website baru yang terus bermunculan, begitu pula dengan bertambahnya jumlah aplikasi mobile hasil produksi dalam negeri. Pertumbuhan developer di Indonesia yang terus bertambah dan tetap memiliki rasa untuk berkreasi-lah yang turut memiliki andil dalam berkembangnya dunia digital disini.
Salah satu isu yang sering ditemui dalam membuat layanan berbasis internet ini adalah sulitnya memiliki konten yang berkualitas dan dalam jumlah yang banyak dan konsisten. Karena untuk mendapatkan konten yang memiliki kriteria tersebut akan membutuhkan biaya dan personil data entry yang kompeten dan dalam jumlah yang tidak sedikit.
Cara cepat yang bisa dilakukan untuk mendapatkan konten adalah dengan mengambil isi dari website lain atau lebih dikenal dengan teknik web scraping. Apa yang dilakukan web scraping yakni mengambil konten website untuk kemudian dipilah-pilah sesuai dengan informasi yang dibutuhkan. Cara yang bisa digunakan adalah dengan meng-copy paste sebuah website yang dilakukan seseorang secara manual, atau dengan cara otomatis yaitu memparsing seluruh isi website dengan tools atau aplikasi.
Teknik scraping sendiri sudah lama digunakan oleh robot atau crawler, robot tersebut melakukan scraping website untuk digunakan sebagai index di search engine atau untuk web archiving. Contoh penggunaan scraping yang lainnya adalah pada fitur share yang tersedia di website social media. Pada saat kita ingin me-share sebuah link website maka proses yang terjadi dibelakang adalah ada engine yang bertugas untuk melakukan scraping data (biasanya data judul, kutipan isi dan gambar) untuk kemudian ditampilkan pada box share mereka.
Linkedin sharing box
Legalitas
Kita sudah terbiasa sama dua contoh scraping diatas, dan bahkan website kita terbantu apabila website kita ter-index di website pencarian, atau ada yang men-share website kita dengan tampilan yang informatif.
Sudah lama kita menganggap apa yang dilakukan robot/crawler dan social media merupakan hal yang biasa dan legal. Tetapi apakah hal ini berlaku pula apabila scraping digunakan untuk keperluan yang lain? Seperti membuat website aggregator dari situs-situs berita, atau membangun website layanan untuk membandingkan harga produk atau tiket dari beberapa website ecommerce dan ticketing.
Dari contoh diatas kita sudah dibentengi oleh peraturan atau perundangan tentang duplikasi dan distribusi ulang konten, yang diatur di undang-undang ITE atau Undang-undang Hak Cipta. Untuk menindaklanjuti secara hukum lebih mudah, karena bentuk dan buktinya terlihat dengan kasat mata.
Tetapi teknik web scraping telah bermetamorfosis ke bentuk yang lebih canggih. Web scraping tidak lagi sekedar mengambil konten dari website, tetapi telah memiliki kemampuan untuk berperilaku dan melakukan aksi seperti yang dilakukan oleh manusia.
Perilaku manusia seperti memasukan input, klik tombol submit, menggerakan mouse, scroll halaman, mampu di replikasi oleh aplikasi. Dari sisi positif, kemampuan ini bisa digunakan untuk pekerjaan QA dalam mensimulasikan perilaku user terhadap halaman website. Tetapi dari sisi lainnya, kemampuan Web scraping yang sekarang dapat disalahgunakan untuk hal-hal yang negatif dan destruktif.
Resiko dan Ancaman
Apa yang bisa dilakukan dengan web scraping tidak sebatas pengambilan konten dan informasi saja, tetapi pada saat di aplikasikan sebagai tools yang mampu menirukan perilaku manusia dalam browsing, hasilnya adalah akan tercipta aplikasi robot yang pintar.
Proses di eCommerce seperti pemilihan produk, menentukan kuantitas barang, proses autentikasi, pengisian data pribadi, sampai proses pembayaran, semua dapat dilakukan secara otomatis oleh robot. Begitu pula otomatisasi ini dapat dilakukan untuk booking tiket penerbangan, jual/beli saham, transaksi keuangan lainnya, pemesanan acara konser, dan masih banyak lagi.
Lalu dimanakah letak sisi negatif dari web scraping ini? mari kita coba pisahkan dari sudut pandang bisnis dengan teknis, dan bagaimana contoh kasusnya pada dunia nyata.
Perspektif Bisnis
Dengan otomatisasi web seperti yang dicontohkan diatas, ternyata memiliki dampak negatif pula ke area bisnis. Yang akan terpengaruh disini adalah reputasi perusahaan, SOP dan proses bisnis internal. Dari sisi pengaruhnya bisa berdampak cepat pada hitungan jam, atau menggrogoti bisnis secara lambat tapi pasti. Dan beberapa resiko yang mungkin akan timbul adalah:
- Data statistik: Setiap rekues yang dilakukan oleh web robot sangat kecil kemungkinannya akan tercatat oleh aplikasi statistik, sehingga akan menyebabkan data analisis tersebut akan menjadi bias. Dan dengan ketidak akuratannya data statistik tersebut, tim bisnis marketing akan beresiko salah dalam menganalisa pasar, perilaku konsumen, keefektifitasan akusisi dan user engagement, sampai saat mengambil keputusan bisnis.
- Unfair marketing campaign: Kejadian ini sering terjadi pada saat sebuah website yang mengadakan kampanye marketing terutama dengan promosi harga khusus atau diskon. Web robot akan memonitoring harga produk, dan apabila produk tersebut sudah masuk ke masa promosi, secara otomatis web robot tersebut akan membeli produk yang sedang di promosikan. Apa yang terjadi disini adalah, persaingan antar calon pembeli dalam memperebutkan produk-produk promosi menjadi tidak adil dan dimonopoli oleh teknologi, bad user experience.
- Bulk Order: Dengan automation ini web robot dimungkinkan untuk membuat random dan distributed order fiktif, bisa itu di ecommerce atau di website ticketing. Tujuannya bisa beragam, mungkin ingin merusak bisnis kompetitor dengan menghabiskan stock barang yang dimilikinya, atau hanya sekedar seorang oportunis yang mengambil barang promosi dengan jumlah besar, dan kemudian mengambil keuntungan dengan menjualnya kembali.
- Search Engine Deoptimization: Pada saat orang mengambil konten kita untuk ditampilkan kembali di website mereka, maka SEO website kita akan berpotensi mendapatkan nilai yang rendah. Hal ini disebabkan karena beberapa penyedia layanan search engine akan mengabaikan website yang kedapatan kontennya duplikat dengan website yang lain.
Ancaman pada Teknologi
Apa yang dilakukan web robot tidak akan semasif dan sebesar load yang datang dari DDOS. Bahkan masih bisa dikategorikan sebagai traffic yang ‘hampir’ serupa dengan traffic pengunjung website pada umumnya. Tetapi seperti pada serangan yang mengincar web application, apa yang dilakukan web robot lebih terfokus dan lebih tertuju pada fungsionalitas website targetnya.
Beberapa contoh dampak teknis yang dapat diakibatkan dari serangan web robot ini adalah:
- Bypass cache: Tidak seperti web scraping yang hanya mengambil konten dari halaman utama yang biasanya di cache, web robot menarget halaman-halaman yang hampir tidak pernah dicache, dikarenakan aktifitas yang dilakukannya lebih kedalam halaman yang tidak mungkin di cache (shopping cart, login, transaction history). Dan akibat dari mengakses halaman-halaman ini adalah membuat proses di layer data (database, json, xml) menjadi meningkat.
- Out of resource: Dengan meningkatnya transaksi yang terjadi di layer data maka dapat mengakibatkan respons dari layer tersebut menjadi lambat, dan pada akhirnya antrian di server akan menjadi terus menumpuk sampai server kehabisan resource (cpu, memory, connection, open files).
- System overload: Apabila teknik ini dikombinasikan dengan serangan DDos yang menyerang secara serempak dan terdistribusi, maka dengan menggabungkan DDOS dengan teknik web robot maka hasilnya akan menjadi serangan Dos yang paling efektif dan efisien dalam membuat sistem dari target menjadi down dan tidak dapat diakses.

Combining DOS + Web Robot
Pertahanan Web Scraping
Pertahanan yang paling efektif dalam menaggulangi web robot ini tentunya adalah memblokir IP tersebut agar tidak dapat mengakses website kita lagi, atau me-redirect-nya ke halaman captcha, seperti yang dilakukan google.com apabila mereka mencurigai IP yang mengaksesnya berasal dari web robot. Masalahnya adalah, captcha
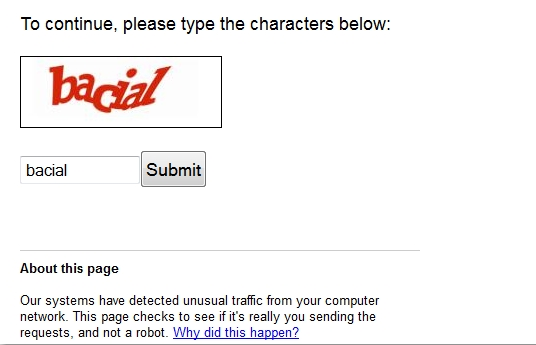
Google akan menghadang traffic yang mencurigakan dengan mengarahkannya ke halaman captcha
Penggunaan Captcha sangat efektif dalam mendeteksi antara user sesungguhnya dengan robot, tetapi harga yang harus dibayar adalah ketidak nyamanan user pada saat berinteraksi dengan website kita.
Permasalahan dari proteksi website kita terhadap web robot atau web scraping adalah, bagaimana cara mengidentifikasikan request tersebut berasal dari user biasa atau robot, karena keduanya melakukan single request yang sulit dideteksi oleh firewall.
Dan juga bagaimana memisahkan traffic yang berasal dari web scraping dengan yang datang dari crawler, karena keduanya memiliki karakteristik request yang sama, yakni sama-sama mengakses website hanya untuk mengambil kontennya saja.
Tidak seperti jumlah produk keamanan seperti Anti-virus, Firewall, WAF yang banyak pilihannya, Solusi anti-scraping tidak banyak tersedia di pasaran. Jenisnya sendiri ada dua macam, ada yang hanya berfungsi untuk mengidentifikasikan traffic yang dicurigai sebagai scraper, ada pula yang menyediakan berikut dengan fitur untuk mengintegrasikan dengan perangkat infrastruktur kita. Dengan mengintegrasikan dengan perangkat ini artinya kita dapat melalukan action secara otomatis tanpa perlu sentuhan manusia.
Dua hal yang paling penting untuk disadari pada saat memilih teknologi yang akan digunakan ini adalah, pahami arsitektur aplikasi yang kita kelola, agar fungsi dari anti-scraping ini dapat bekerja dengan efektif tanpa menghabiskan resource server.
Dan yang kedua adalah, beri waktu yang cukup untuk teknologi dan tim operasional untuk mempelajari hasil dari analisa anti-scraping ini. Jangan sampai pengalaman user dalam mengakses website kita menjadi terganggu dan alih-alih malah merusak bisnis jangka panjang.
Leave a Reply